互聯(lián)網(wǎng)信息服務(IIS)管理器 如何打開與基本概念
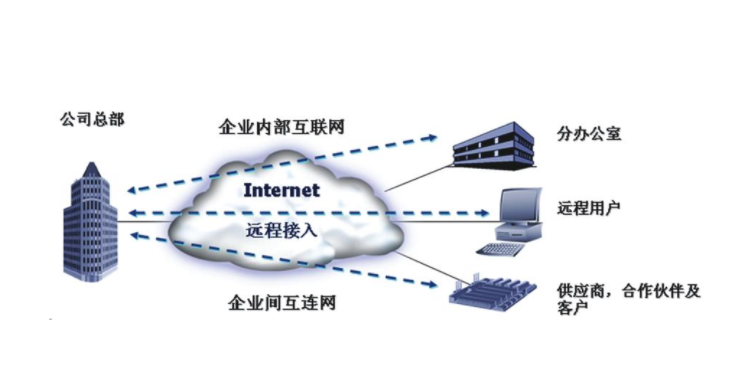
互聯(lián)網(wǎng)信息服務(Internet Information Services,簡稱IIS)是微軟公司開發(fā)的用于Microsoft Windows的Web服務器軟件。它用于托管網(wǎng)站、Web應用程序和Web服務。用戶提到的“LLS管理器”很可能是指“IIS管理器”,即IIS的管理控制臺。
如何打開IIS管理器?
在Windows操作系統(tǒng)中,有幾種常用方法可以打開IIS管理器(Internet Information Services (IIS) Manager):
- 通過控制面板(經(jīng)典方法):
- 點擊“開始”菜單或按鍵盤上的Windows鍵。
- 在搜索框中輸入“控制面板”并打開它。
- 在控制面板中,選擇“系統(tǒng)和安全”。
- 點擊“管理工具”。
- 在管理工具文件夾中,找到并雙擊“Internet Information Services (IIS) 管理器”。
- 通過運行命令(快速方法):
- 按
Windows鍵 + R打開“運行”對話框。
- 輸入
inetmgr并按回車鍵或點擊“確定”。
- 這是最快捷、最常用的方式。
- 通過Windows搜索(便捷方法):
- 在任務欄的搜索框或“開始”菜單的搜索框中,直接輸入 “IIS” 或 “Internet Information Services”。
- 在搜索結果中,通常會直接出現(xiàn)“Internet Information Services (IIS) 管理器”,點擊即可打開。
- 通過服務器管理器(適用于Windows Server):
- 在Windows Server系統(tǒng)中,通常可以從“服務器管理器”的“工具”菜單中直接選擇“IIS管理器”。
前提條件:確保IIS已安裝
在嘗試打開IIS管理器之前,請確保您的Windows系統(tǒng)已經(jīng)安裝了IIS功能。默認情況下,家庭版Windows可能未安裝,專業(yè)版、企業(yè)版和Windows Server通常需要手動啟用。
安裝/啟用IIS的步驟:
1. 打開“控制面板” -> “程序” -> “啟用或關閉Windows功能”。
2. 在彈出的窗口列表中,找到并勾選“Internet Information Services”。
3. 您可以點擊其前方的“+”號展開,選擇需要的子功能(如Web管理工具、萬維網(wǎng)服務等)。對于基本的管理,確保“Web管理工具”下的“IIS管理控制臺”被選中。
4. 點擊“確定”,Windows將安裝所選功能。安裝完成后可能需要重啟計算機。
IIS管理器界面簡介
打開IIS管理器后,您會看到一個分欄界面:
- 左側連接面板: 以樹形結構顯示服務器和站點。您可以在這里管理服務器、網(wǎng)站、應用程序池等。
- 中間主工作區(qū): 當選中左側的某個節(jié)點(如一個網(wǎng)站)時,這里會顯示對應的功能圖標或詳細設置項,如“默認文檔”、“身份驗證”、“SSL設置”等。
- 右側操作面板: 提供針對當前選中節(jié)點的可執(zhí)行操作,如“啟動”、“停止”、“重新啟動”、“綁定”、“基本設置”等。
基本用途
通過IIS管理器,您可以執(zhí)行以下核心操作:
- 創(chuàng)建和管理網(wǎng)站: 設置物理路徑、綁定域名和端口(如80端口用于HTTP,443用于HTTPS)。
- 配置應用程序池: 管理網(wǎng)站運行的工作進程、.NET版本、回收條件等,這對應用程序的性能和穩(wěn)定性至關重要。
- 設置安全性: 配置身份驗證方式(匿名、Windows、表單等)、IP地址限制、請求篩選等。
- 管理證書和SSL: 為網(wǎng)站綁定SSL證書以啟用HTTPS安全訪問。
- 配置默認文檔和錯誤頁: 設置網(wǎng)站的主頁文件和自定義錯誤響應。
- 啟用日志記錄: 配置IIS日志的存放位置和記錄字段,用于分析和排查問題。
###
對于需要在Windows平臺上搭建和管理Web服務的用戶來說,IIS管理器是一個必不可少的工具。記住運行命令 inetmgr 是最快的打開方式。在使用前,請確認IIS功能已正確安裝。通過這個圖形化管理器,即使不熟悉命令行,也能相對方便地完成大多數(shù)網(wǎng)站和應用程序的配置工作。
如若轉載,請注明出處:http://www.ruanchuo.cn/product/66.html
更新時間:2026-06-19 14:24:21