深圳市好流量信息服務(wù)有限公司銷售不合格互聯(lián)網(wǎng)信息服務(wù)產(chǎn)品案剖析
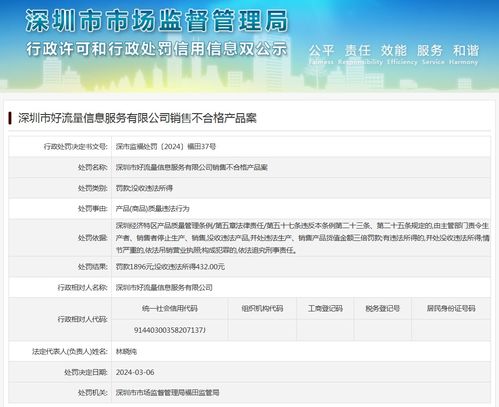
隨著互聯(lián)網(wǎng)經(jīng)濟(jì)的蓬勃發(fā)展,互聯(lián)網(wǎng)信息服務(wù)已成為社會經(jīng)濟(jì)運(yùn)行不可或缺的基礎(chǔ)設(shè)施。行業(yè)快速擴(kuò)張的部分企業(yè)在服務(wù)質(zhì)量與合規(guī)性方面的問題也逐漸暴露。深圳市市場監(jiān)管部門對“深圳市好流量信息服務(wù)有限公司”(以下簡稱“好流量公司”)涉嫌銷售不合格互聯(lián)網(wǎng)信息服務(wù)產(chǎn)品的案件進(jìn)行了查處,為行業(yè)敲響了警鐘。此案不僅揭示了當(dāng)前互聯(lián)網(wǎng)信息服務(wù)市場存在的亂象,也凸顯了強(qiáng)化監(jiān)管、保障用戶權(quán)益的緊迫性。
一、 案件回顧:違規(guī)事實(shí)與查處經(jīng)過
據(jù)公開信息顯示,好流量公司主要經(jīng)營業(yè)務(wù)為提供網(wǎng)絡(luò)推廣、流量導(dǎo)入、數(shù)據(jù)分析等互聯(lián)網(wǎng)信息服務(wù)。在市場監(jiān)管部門的例行檢查及后續(xù)調(diào)查中,發(fā)現(xiàn)該公司存在以下核心問題:
- 產(chǎn)品(服務(wù))質(zhì)量不合格:該公司向客戶承諾的“精準(zhǔn)流量導(dǎo)入”、“高轉(zhuǎn)化率推廣”等服務(wù),在實(shí)際執(zhí)行中遠(yuǎn)未達(dá)到合同約定的技術(shù)指標(biāo)和效果。其使用的技術(shù)手段陳舊,數(shù)據(jù)存在大量虛假與刷量成分,未能為客戶帶來真實(shí)有效的訪問與商業(yè)轉(zhuǎn)化,屬于典型的“不合格產(chǎn)品”。
- 宣傳內(nèi)容虛假夸大:在營銷過程中,該公司通過其官網(wǎng)、宣傳資料等渠道,使用“行業(yè)領(lǐng)先”、“絕對精準(zhǔn)”、“ guaranteed效果”等絕對化用語和無法證實(shí)的承諾,對服務(wù)效果進(jìn)行虛假或引人誤解的商業(yè)宣傳,誤導(dǎo)了消費(fèi)者。
- 合同履行存在欺詐:部分客戶反映,在服務(wù)效果不達(dá)標(biāo)后,公司以各種理由推諉,拒絕按合同約定承擔(dān)違約責(zé)任或退款,侵害了消費(fèi)者合法權(quán)益。
基于以上事實(shí),市場監(jiān)管部門認(rèn)定好流量公司的行為違反了《中華人民共和國產(chǎn)品質(zhì)量法》、《中華人民共和國反不正當(dāng)競爭法》、《中華人民共和國廣告法》以及《互聯(lián)網(wǎng)信息服務(wù)管理辦法》等相關(guān)規(guī)定,構(gòu)成了銷售以次充好、以虛假宣傳誤導(dǎo)消費(fèi)者的不合格互聯(lián)網(wǎng)信息服務(wù)的行為。依法對其作出了責(zé)令立即停止違法行為、處以罰款、并要求其向受損客戶退賠等行政處罰。
二、 深層剖析:行業(yè)亂象與風(fēng)險根源
“好流量公司”一案并非孤例,它折射出互聯(lián)網(wǎng)信息服務(wù)行業(yè),尤其是在營銷推廣、流量獲取等細(xì)分領(lǐng)域的一些共性痛點(diǎn):
- “效果”難以標(biāo)準(zhǔn)化衡量:與實(shí)體商品不同,互聯(lián)網(wǎng)信息服務(wù)的“質(zhì)量”和“效果”缺乏國家或行業(yè)統(tǒng)一的強(qiáng)制性標(biāo)準(zhǔn)。點(diǎn)擊量、曝光量、轉(zhuǎn)化率等指標(biāo)極易通過技術(shù)手段造假,為不法商家提供了操作空間。
- 技術(shù)壁壘與信息不對稱:服務(wù)提供方在技術(shù)原理、數(shù)據(jù)真實(shí)性方面占據(jù)絕對信息優(yōu)勢,普通企業(yè)客戶往往難以鑒別服務(wù)背后的真實(shí)情況,只能依賴服務(wù)商的承諾,從而容易落入陷阱。
- 市場惡性競爭與短期逐利:在激烈的市場競爭下,部分企業(yè)為搶奪客戶,不惜夸大宣傳,以低價承諾不切實(shí)際的效果,陷入“劣幣驅(qū)逐良幣”的惡性循環(huán),忽視了服務(wù)本身的價值與長期信譽(yù)。
- 監(jiān)管面臨新挑戰(zhàn):互聯(lián)網(wǎng)服務(wù)虛擬化、跨地域、技術(shù)迭代快的特點(diǎn),對傳統(tǒng)監(jiān)管模式提出了挑戰(zhàn)。違規(guī)行為隱蔽性強(qiáng),取證難度較大,需要監(jiān)管手段持續(xù)升級。
三、 啟示與建議:構(gòu)建健康有序的服務(wù)市場
此案的查處具有重要的警示和示范意義,為行業(yè)健康發(fā)展指明了方向:
- 對企業(yè)而言,誠信與質(zhì)量是立身之本:互聯(lián)網(wǎng)服務(wù)企業(yè)必須摒棄“一錘子買賣”的短視思維,將資源投入到提升核心技術(shù)、優(yōu)化真實(shí)服務(wù)效果上來。建立透明、可驗(yàn)證的服務(wù)質(zhì)量評估體系,用真實(shí)價值贏得市場。
- 對消費(fèi)者(企業(yè)客戶)而言,需提升鑒別能力:在選擇服務(wù)商時,應(yīng)仔細(xì)核查其資質(zhì)、過往成功案例(要求提供可驗(yàn)證的數(shù)據(jù)),審慎對待過度夸張的承諾,在合同中明確約定關(guān)鍵績效指標(biāo)(KPIs)、驗(yàn)收標(biāo)準(zhǔn)及違約責(zé)任,保留好相關(guān)證據(jù)。
- 對行業(yè)而言,亟需推動標(biāo)準(zhǔn)與自律:相關(guān)行業(yè)協(xié)會應(yīng)積極牽頭,研究制定細(xì)分領(lǐng)域的服務(wù)質(zhì)量指導(dǎo)標(biāo)準(zhǔn)或團(tuán)體標(biāo)準(zhǔn),建立行業(yè)誠信檔案和黑名單制度,引導(dǎo)企業(yè)自覺規(guī)范經(jīng)營。
- 對監(jiān)管部門而言,須實(shí)施精準(zhǔn)動態(tài)監(jiān)管:充分利用大數(shù)據(jù)、云計算等技術(shù)手段,加強(qiáng)對互聯(lián)網(wǎng)廣告、流量數(shù)據(jù)等的監(jiān)測分析,建立跨部門協(xié)同監(jiān)管機(jī)制。對于虛假宣傳、數(shù)據(jù)造假、銷售不合格服務(wù)等行為,保持高壓打擊態(tài)勢,提高違法成本。暢通消費(fèi)者投訴舉報渠道,形成社會共治局面。
深圳市好流量信息服務(wù)有限公司銷售不合格產(chǎn)品案,是一次對互聯(lián)網(wǎng)信息服務(wù)市場秩序的及時整頓。它清晰地表明,無論商業(yè)模式如何創(chuàng)新,技術(shù)如何迭代,商業(yè)活動的基本底線——誠信守法、質(zhì)量為本——永遠(yuǎn)不會改變。只有企業(yè)、消費(fèi)者、行業(yè)組織與監(jiān)管部門共同努力,才能滌清市場環(huán)境,推動互聯(lián)網(wǎng)信息服務(wù)行業(yè)從“流量至上”走向“價值為王”的高質(zhì)量發(fā)展階段,真正賦能實(shí)體經(jīng)濟(jì)數(shù)字化轉(zhuǎn)型。
如若轉(zhuǎn)載,請注明出處:http://www.ruanchuo.cn/product/57.html
更新時間:2026-06-19 02:09:54